+
+  =
= 
Garett Rogers hat sich mal wieder eingehend mit Googles
robots.txt beschäftigt und hat dabei etwas sehr interessantes entdeckt: Es handelt sich dabei um den Nachfolger von
Google Base und/oder
Froogle - so ganz genau lässt sich das bisher noch nicht sagen. Es handelt sich um eine Suchmaschine die die Datenbank von Base nach Produkten durchsucht und diese dann auf einer
Google Map darstellt.
Die Suchmaschine
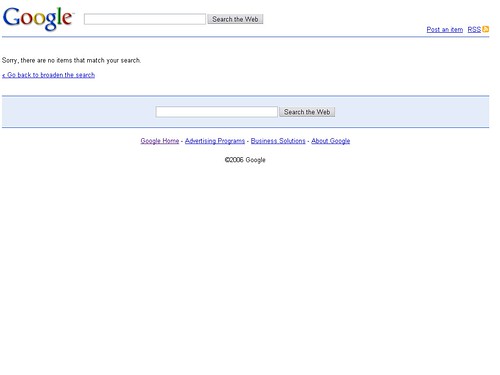
Die Suchmaschine liegt im Verzeichnis
google.com/base/s2/ welches nur die Meldung "
Sorry, there are no items that match your search" ausgibt. s2 steht hierbei wohl für "Search 2", also die zweite Version der Suche. Nur durch die manuelle Eingabe der Suchparameter in die URL bekommt man die neue Suchmaschine aber auch wirklich in Aktion zu sehen - das Suchfeld oberhalb des Meldung leitet auf die Websuche weiter.
Beispielsuche
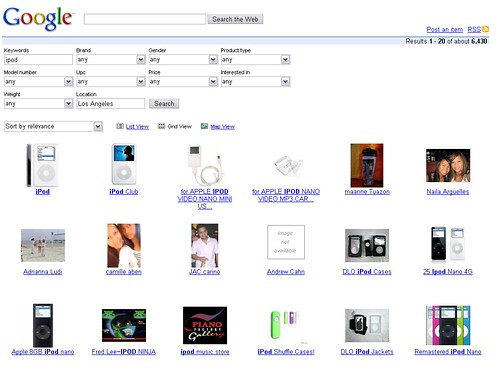
Sucht man dann nach einem Begriff, z.B.
iPod, bekommt man eine Liste mit iPods angezeigt - leider stehen diese größtenteils nicht zum Verkauf sondern sind nur aus Spaß an der Freude in den Base-Index eingetragen worden. Die Suche kann dabei um viele Kleinigkeiten - vermutlich ausgewählt anhand der Base-Labels - verfeinert und eingeschränkt werden. Leider sind auch hier die Eintragungen nicht sehr hilfreich - oder warum sollte man bei einem iPod das Geschlecht auswählen?
Aber wenn wir diese kleinen Fehler - die Google vor dem Release sicherlich noch beheben wird (und muss) - außen vor lassen sieht die Suchmaschine doch schon sehr interessant aus. Beim Mouse-Over über ein Produkt wird dies vergrößert und mit weiteren Informationen versehen - z.B. wohin man bei einem Klick weitergeleitet wird. Außerdem erscheint auch der Preis (falls der iPod zum Verkauf steht) und eine kurze Beschreibung.
Beispielsuche mit Karte
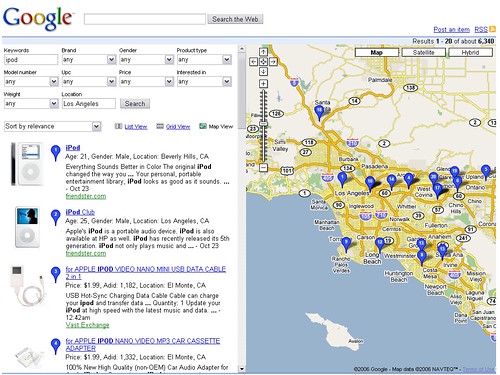
Aktiviert man jetzt die
Kartenansicht werden nur noch Produkte dargestellt die Geo-Informationen enthalten und somit auf der Karte angezeigt werden können. Meistens handelt es sich dabei, wieder dank den merkwürdigen Eintragungen der User, nicht um die Position des Geschäftes sondern um den Wohnort der glücklichen iPod-Besitzer. Ein Klick auf einen Eintrag in der Karte hebt dann die Eintragungen in der Ergebnisliste hervor.
Erster Eindruck
Ob das ganze nun wirklich ein Nachfolger zu
Froogle werden soll ist zwar nicht bekannt, aber die Wahrscheinlichkeit ist schon sehr hoch - schließlich gehört Froogle zu den Auslaufmodellen und wurde schon vor einigen Monaten
teilweise von Base verdrängt. Leider lässt die Möglichkeit der freien Eintragung in Base die Qualität des Produktverzeichnisses sehr stark leiden, wie die Beispielsuche nach einem iPod zeigt.
Vielleicht soll das ganze aber auch nur eine erweiterte Suche für Base werden, bei dem die Suchfunktion vor kurzem
verschwunden ist. Meiner Meinung nach ist so ein Suchinterface genau das richtige um die Untiefen von Base richtig zu durchsuchen - aber leider bringt auch diese Suche keine wirkliche Ordnung in das Datenchaos. Ich bleibe bei meiner Meinung dass Google sich mit Base verspekuliert hat und diese Datenmassen niemals richtig ordnen, nutzen und anbieten werden kann - dafür ist zuviel Müll enthalten.
Siehe auch:
»
Neuer robots.txt-Eintrag: google.com/base/s2/
»
Google Base S2
»
Google Base S2 iPod
[
ZDNet-Blog]