Google betreibt für die zahlreichen Cloud-Dienste eine gewaltige Infrastruktur mit mehr als einem Dutzend selbst betriebenen Rechenzentren und Millionen von Servern. Dass in diesem großen Verbund ständig Probleme auftreten und Hardware getauscht werden muss, ist schon rein statistisch nicht außergewöhnlich, sondern Normalität. In einem Blogbeitrag berichten Googles Ingenieure nun von einem Vorfall, der so gar nichts mit den High Tech-Komponenten zu tun hat.


Aktionen bei Amazon: Echo Smart Speaker & Displays, Fire-Tablets & TV reduziert – so nutzt ihr Google-Dienste
Die gesamte Infrastruktur in Googles Rechenzentren wird ständig auf diverse Parameter von der Leistung bis zur Temperatur überwacht, sodass Probleme und defekte Komponenten sehr schnell aufgespürt und getauscht werden können – Alltag in einem Rechenzentrum dieser Größe. Jetzt berichtet das Team von einem interessanten Fall, den man in der Form wohl nicht erwartet hätte und der sich auch nicht mit Software-Tricks oder anderen gängigen Methoden beheben ließ.
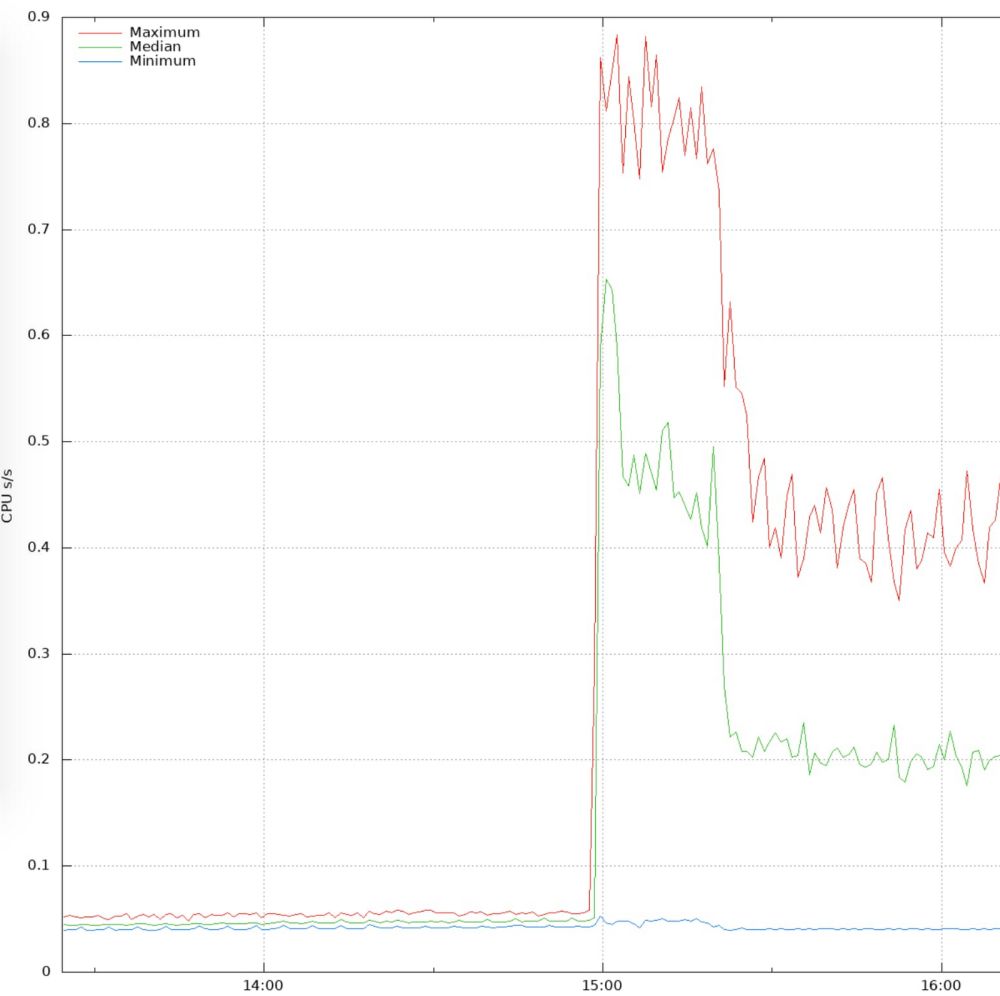
Eine Einheit in einem Rechenzentrum meldete eine extrem ansteigende Temperatur einzelner Komponenten, sodass die Last automatisiert auf diesem System automatisiert heruntergefahren wurde, um eine Überhitzung zu verhindern. Das half allerdings nur bedingt, denn die Temperatur wollte dennoch nicht signifikant sinken – also machte sich das Team auf Fehlersuche. Problematisch daran war es, dass durch das Herunterfahren der Leistung auch Nutzer beeinträchtigt werden könnten, sodass der Traffic für diesen Bereich gesenkt und an andere Einheiten weitergegeben wurde.
Google Fotos: Deine schönsten Erinnerungen – Stories-Klon erhält neue Kriterien & Fotoabzüge (Screenshots)



Nach längerem Suchen machte man dann den Fehler ausfindig, der so gar nichts mit den üblichen High Tech-Komponenten vom Speicher bis zum Prozessor zu tun hatte – wie ihr auf obigem Foto schon erkennen könnt. Eine Radrolle eines Serverschranks ist unter der Last der Komponenten zusammengebrochen und hat dafür gesorgt, dass der gesamte Serverschrank in Schieflage gerät und die Kühlung nicht mehr effektiv arbeiten kann.
Das Rad ist natürlich ein Cent-Artikel, kommt in der Form aber Tausendfach zum Einsatz, sodass man nun auch in diesem Bereich Verbesserungen vornehmen wird – denn in den Rechenzentren gilt die Regel, dass jedes Problem eine Neuheit sein muss. Mit anderen Worten: Jedes Problem muss nicht nur behoben, sondern ein erneutes Auftreten so gut es geht verhindert werden. Und das jetzt eben auch in einem Bereich, dem man bisher wohl kaum Beachtung geschenkt hat.
Es ist sicher nur eine kleine Anekdote von vielen, aber schon im Google-Blog heißt es, dass bei einer so gigantischen Infrastruktur wie der von Google eben Probleme auftreten, die normalerweise nur eine ein Million zu eins-Chance haben. Die ganze Geschichte inklusive der Kommunikation findet ihr im Google Cloud-Blog.