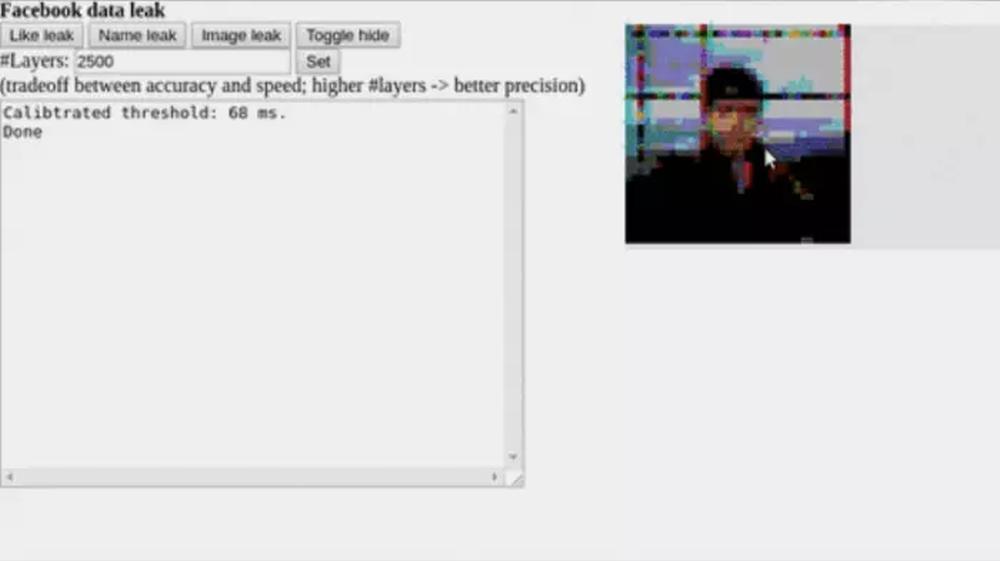
Chrome Sicherheitslücke: CSS-Funktion ermöglichte es, eingebettete Webseiten auszulesen (Demo)

Browser gehören heute zu den wichtigsten Anwendungen überhaupt und werden von den meisten Nutzern für alle alltäglichen Aufgaben verwendet. Sicherheitslücken sind dementsprechend schwerwiegend und können, wenn sie erfolgreich ausgenutzt werden, auch Daten abgreifen, an die es auf normalem Wege eigentlich kein Herankommen gäbe. Im Chrome-Browser und auch im Firefox gab es über ein Jahr lang eine Lücke, die mithilfe von CSS unbefugt Daten abgreifen konnte – wenn auch nur in geringem Umfang.
In Browsern kommen viele verschiedene Programmiersprachen zum Einsatz, die allesamt unterschiedliche Konzepte haben und wie Zahnräder ineinander greifen: HTML, CSS und JavaScript (Ich weiß, dass die ersten beiden keine „Programmiersprachen“ sind). Alle haben nicht nur ihre eigenen Sprachen, sondern auch unterschiedliche Sicherheitsschranken, die sich aber gegenseitig aushebeln könnten. Jetzt ist ein Fall publik geworden, bei dem genau das möglich war.
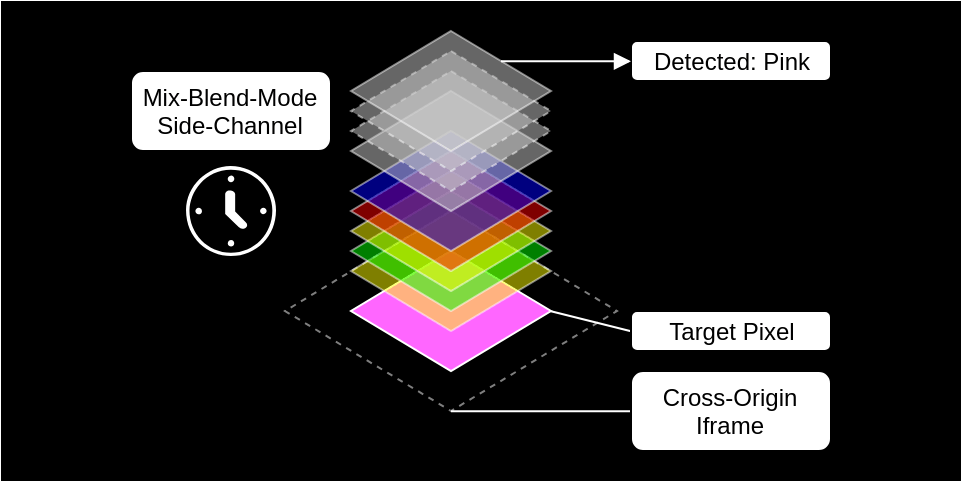
Wird in einer Webseite eine andere Webseite per iframe eingebettet, hat die darüber liegende Instanz normalerweise keinen Zugriff darauf, was in dem eingebetteten Dokument passiert. Doch Sicherheitsforschern ist es vor einiger Zeit gelungen, diesen Schutz mit einer Kombination aus CSS und JavaScript auszuhebeln. Dazu haben sie eine ganze Masse an DIV-Containern über den eingebetteten Inhalt gelegt und diesem mit dem mix-blend-mode jeweils unterschiedliche Transparenzen gegeben. Durch die Masse an Containern nimmt es etwas Zeit in Anspruch, dass der Browser dies darstellen kann.
Diese Zeit bis zur Darstellung wird per JavaScript millisekundengenau gemessen und gibt Aufschluss darüber, welche Farbe sich darunter befindet. So lässt sich Pixel für Pixel auslesen, welcher Inhalt sich darunter befindet. Das benötigt zwar viel Zeit und ist nicht für ein „Live-Lauschen“ geeignet, kann aber dennoch einige Rückschlüsse liefern. Die Forscher erklären, dass sich so z.B. der Facebook-Name eines Nutzers ohne sein Wissen auslesen lässt.
Dazu wird ein Facebook-Widget integriert, das DIV darüber gelegt und der angezeigte Name Pixel für Pixel erkannt. Hält man den Nutzer lange genug auf der Webseite, ist das problemlos möglich. Das funktioniert genauso mit dem Profilbild, dem Like-Status einer Webseite und vielem mehr.
Die Lücke ist seit längerer Zeit gestopft und ist im Chrome-Browser schon ab Version 63 (aktuell ist 67) und im Firefox seit der Version 60 nicht mehr nutzen. Der Exploit wurde aber erst jetzt veröffentlicht, um sicher zu gehen, dass kein Nutzer davon betroffen sein kann. Die Forscher halten es aber durchaus für möglich, dass durch die Kombination der drei Sprachen und vieler weiterer Technologien noch andere Angriffe möglich sind, die jetzt nur noch nicht bekannt sind.
Das Problem ist zwar behoben, aber die Funktionsweise dieser Lücke lässt sich auf einer eigens dafür geschaffenen Webseite auch weiterhin nachvollziehen. Auf dieser Demoseite kann man sowohl den Nutzernamen als auch das Profilfoto und den Like-Status des eigenen Facebook-Profils auslesen lassen, ohne dass die Webseite dazu Zugang haben dürfte.
Durch die Umsetzung des CSS Blend Mode waren nur noch Chrome und Firefox betroffen, während die Engines des Safari und Edge diese Lücke nicht aufgewiesen haben.
» Erklärung der Lücke
» Demoseite
[heise]
GoogleWatchBlog bei Google News abonnieren | GoogleWatchBlog-Newsletter
Teile diesen Artikel:




