

Spracherkennung ist seit vielen Jahren ein großes Thema und wird schon seit mindestens zwei Jahren erforscht und von diversen Unternehmen angeboten. Erst in den vergangenen Jahren wurden aber so große Schritte gemacht, dass heute jeder Nutzer völlig normal und ohne Anstrengung mit seinem Smartphone oder Smart Speaker kommunizieren kann. Google hat nun eine neue Technologie vorgestellt, die sogar mit mehreren Sprechern gleichzeitig umgehen kann.
Bei frühen Spracherkennungssystem musste man noch recht langsam und vor allem sehr deutlich reden. Außerdem musste darauf geachtet werden, möglichst keine Geräusche im Hintergrund zu haben, die die Erkennung der Sprache schon wieder negativ beeinflussen konnten. Das ist zu großen Teilen längst Vergangenheit, sodass selbst Nuschler heute ganz gut mit ihren Sprachassistenten zurechtkommen. Doch wenn mehrere Menschen gleichzeitig reden, ist das bis heute ein Problem.

Jeder kennt den Effekt: Man befindet sich in einem Raum mit vielen Menschen und alle sprechen durcheinander. In der Masse versteht man kein einziges Wort, aber wenn man sich auf einen Gesprächspartner konzentriert, kann das Gehirn alle anderen „Geräusche“ gut ausblenden. Das ganze nennt sich Cocktailparty Effect und ist für den Menschen auf Dauer zwar auch anstrengend, aber nichts besonders mehr. Für Sracherkennungssysteme hingegen war das bisher das Ende der Fahnenstange.
Google hat nun eine Technologie vorgestellt, die in der Lage ist, eine Stimme einer Person zuzuordnen und diese vollständig herauszustellen. Gezeigt wird das in einigen Beispielvideos, anhand derer ihr das ganze sehr gut sehen und hören könnt. Es wird eine der beiden Personen ausgewählt und dann nur noch die Stimme dieser Person abgespielt. Ganz egal wie viel die andere Person redet oder wie viele Geräusche im Hintergrund sind – die ausgewählte Stimme ist klar und deutlich zu hören.

Beeindruckend ist vor allem folgendes Video, bei dem die Stimme einer Person hervorgehoben wird, die man vorher vielleicht gar nicht wahrgenommen hat. Obwohl sie sehr viel leiser spricht und sich im Hintergrund befindet, ist ihr Telefonat klar und deutlich zu hören, als wenn sie die einzige im Raum gewesen wäre, die etwas gesagt hat. Schaut es euch einfach einmal an.

Noch beeindruckender daran ist, wie Googles Forscher diese Technologie umgesetzt haben. Es ist nicht so, dass einfach Stimme A und Stimme B getrennt werden, sondern auch diese Erkennung verläuft automatisch. Per Analyse von Audio UND Video können die Algorithmen sehr genau erkennen, welche Stimme zu welcher Person gehört. Das funktioniert über eine Kombination der einzelnen Töne im Zusammenhang mit der Auswertung von der Bewegung des Gesichts.
Und so ist es dann möglich, dass direkt eine Person ausgewählt werden und dann auf Laut bzw. Deutlich geschaltet werden kann.

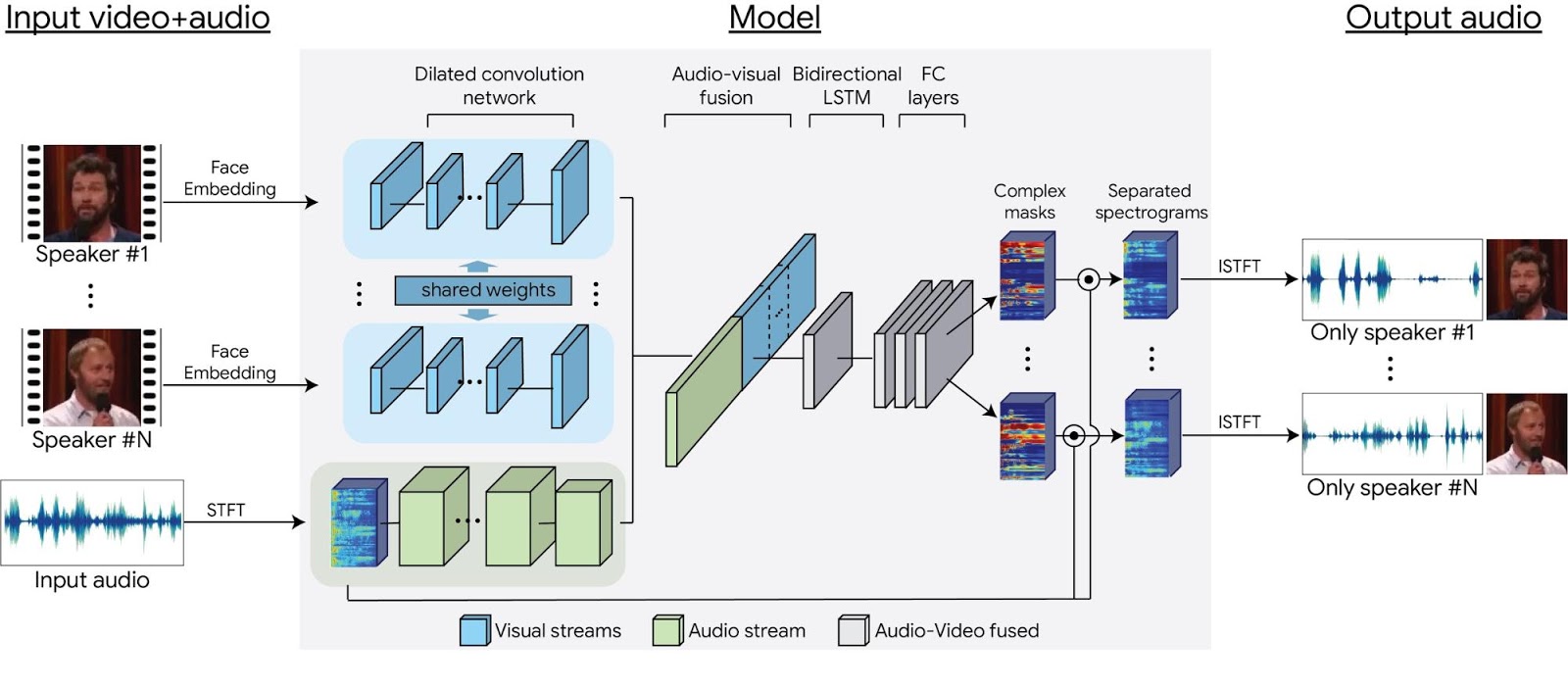
Derzeit funktioniert das nur bei zwei Personen und zwei Stimmen inklusive Hintergrundgeräusche. In Zukunft soll das aber auch bei noch mehr Personen funktionieren und so völlig neue Möglichkeiten bieten. So könnte man dann bspw. einfach einen Raum von vielen durcheinander redenden Menschen aufnehmen und sich anschließend jedes einzelne Gespräch klar und deutlich anhören. Ein Traum für alle Spione, die nun keine Richtmikrofone oder ähnliche Dinge mehr benötigen.
Google möchte diese Technologie in viele Produkte integrieren, hat sich aber noch nicht konkret dazu geäußert. Denkbar wäre vom Google Assistant bzw. Google Home über YouTube und Translate bis hin zu Google Photos viele Dienste. Vorerst kann es aber auch einfach dazu zum Einsatz kommen, die Qualität der Spracherkennung zu verbessern, wenn noch weitere Personen im Raum durcheinander reden.
» Die Webseite des Projekts
» Ankündigung im Google Research Blog