Europäischer Datenschutz: Älterer GWB-Artikel wurde aus der Websuche entfernt (Kurzer Erfahrungsbericht)

Wer einen Blick auf den Titel dieses Blogs wirft, kann davon ausgehen dass wir uns hier zu 100 Prozent mit Artikeln rund um das Thema Google und allen dazugehörigen Bereichen und Themen beschäftigen. Berichte über nicht mit Google in Verbindung stehenden Personen kommen hier eigentlich nicht vor oder sind mit der Lupe zu suchen. Dennoch wurde nun einer unserer Artikel aufgrund des „Europäischen Datenschutzes“ aus den Suchergebnissen für bestimmten Anfragen gelöscht. Und daraus machen wir doch gleich mal einen kleinen Erfahrungsbericht 
Gestern wurden wir von Google mit einer automatischen E-Mail darüber informiert, dass einer unserer Artikel bei bestimmten Anfragen aus den Suchergebnissen in der europäischen Version der Websuche entfernt wurde. Das kommt vermutlich Hunderte oder Tausende male pro Tag bei unzähligen Webseiten vor, aber in unserem Fall ist es doch etwas merkwürdig. Deswegen versuchen wir der Sache auf den Grund zu gehen, denn der betroffene Artikel dürfte einigen Personen oder Organisationen vielleicht nicht gefallen, verletzt aber keine Rechte dritter.
Um welchen Artikel geht es?
Betroffen ist folgender Artikel: Hidden from Google: Sammlung von gelöschten „Recht auf Vergessen“-Links.
In diesem Artikel berichten wir über ein Webportal, dass dazu beitragen wollte, das Recht auf Vergessen in der geplanten Form etwas zu boykottieren – genau so, wie es Google durch diverse Maßnahmen ebenfalls getan hat. Da damals lediglich neun Seiten im Index waren, haben wir einen Screenshot mit allen neun Ergebnissen veröffentlicht. Auf diesem sind auch Namen zu sehen, die aber im Artikel nicht in Textform erwähnt werden. Mittlerweile ist das Portal übrigens nicht mehr Online.
So wurden wir von Google informiert
To: Webmaster of https://www.googlewatchblog.de/,
Due to a request under data protection law in Europe, Google can no longer show one or more pages from your site in Google Search results. This only affects responses to some search queries for names or other personal identifiers that might appear on your pages. Only results on European versions of Google are affected. No action is required from you.
What we’d like you to know:
These pages haven’t been blocked entirely from our search results
They’ve only been blocked on certain searches for names on European versions of Google Search. These pages will continue to appear for other searches.
We aren’t disclosing which queries have been affected.
In many cases, affected queries don’t relate to the name of any person mentioned prominently on the page.
For example, the name might only appear in a comment section.
You can notify us of concerns
If you have additional information regarding the content of a page that you believe warrants a reversal, you can notify Google. Please note that while we read all requests, we do not always respond. Only the registered siteowner can access this form.
Nachforschung
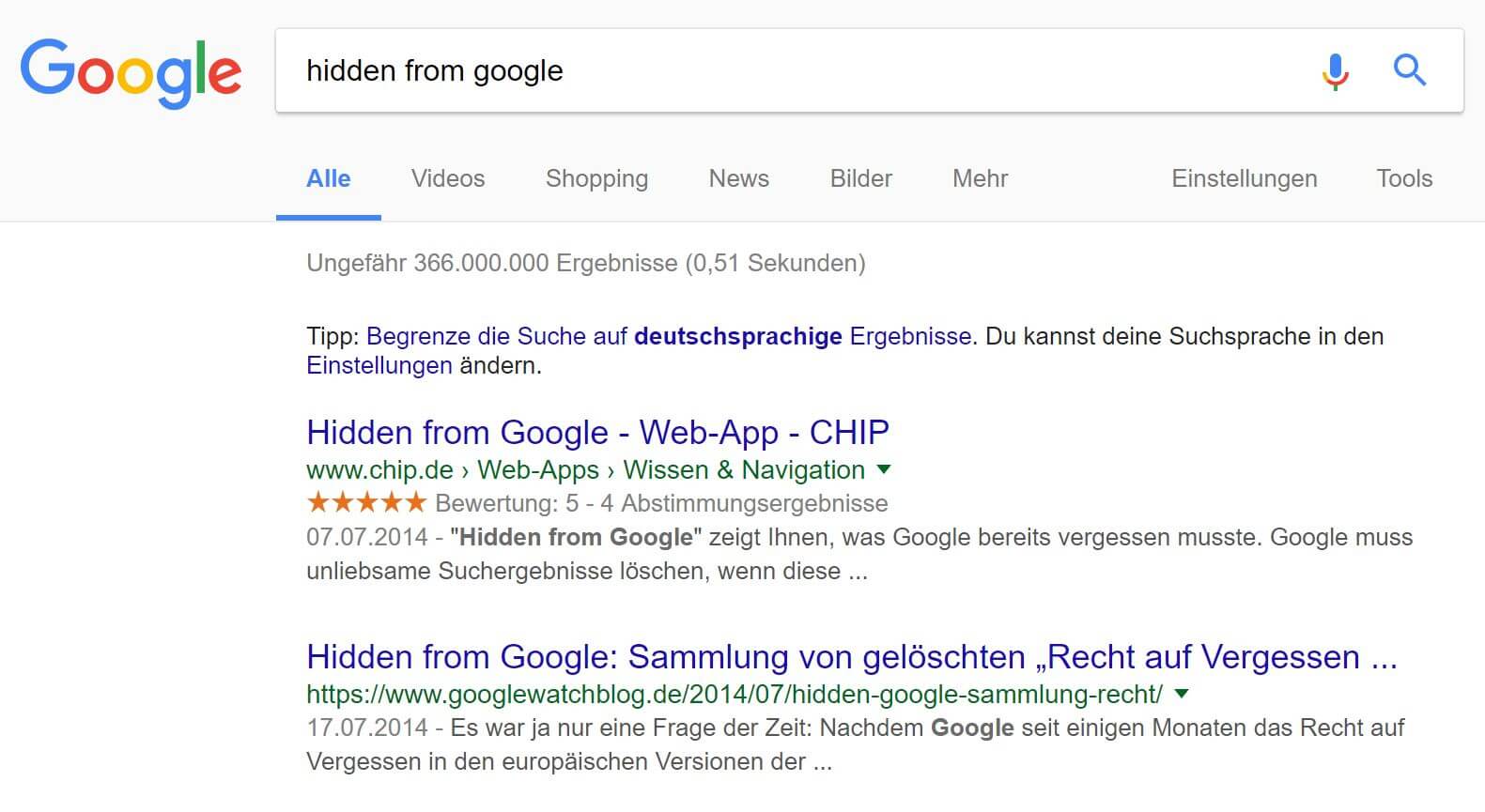
Diese Nachricht enthält nicht wirklich viele Informationen und ist eben eine Standard-Nachricht. Es wird weder ein genauer Grund für die Löschung noch die betroffenen Suchbegriffe genannt. Interessanterweise wird ja nicht einfach der Artikel aus dem Index gelöscht, sondern wird nur bei lediglich einigen Suchbegriffen nicht mehr angezeigt. Gut, damit kann man leben. Immerhin ist der Artikel nun schon weit über drei Jahre alt und erhält ohnehin nur noch sehr wenige Klicks. Dennoch hat es mich ganz persönlich interessiert, um welche Suchbegriffe es eigentlich geht.
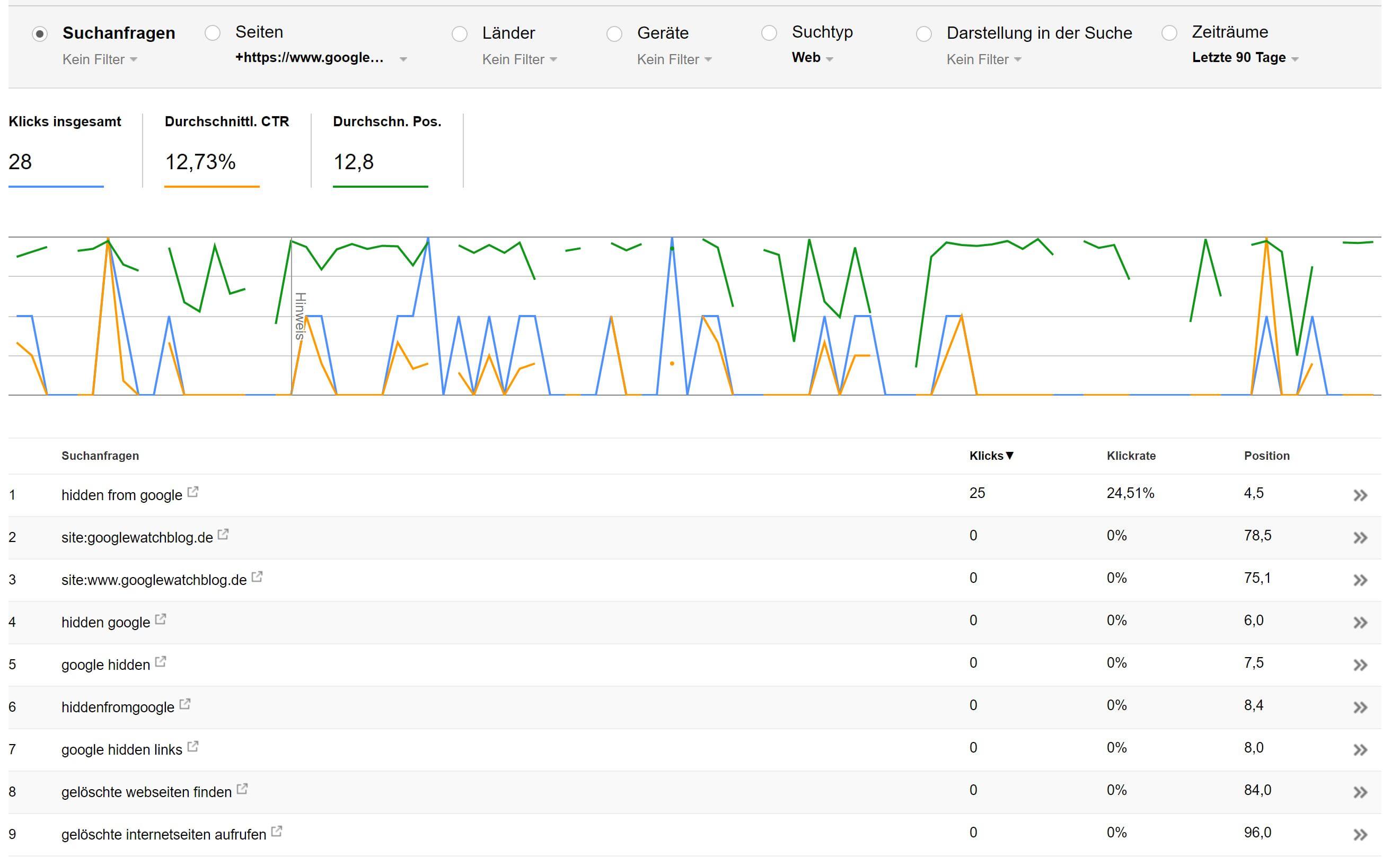
Auf obigem Bild seht ihr alle Suchbegriffe der letzten 90 Tage, unter denen der Artikel gefunden wurde – inklusive Postion in den Ergebnissen. Wirklich relevant ist dabei nur der Begriff „Hidden from Google“ bzw. auch „Google Hidden“. Unter beiden Begriffen ist der Artikel aber zum aktuellen Zeitpunkt immer noch zu finden und wurde mit Sicherheit nicht entfernt. Daraus werden wir also auch nicht schlauer.
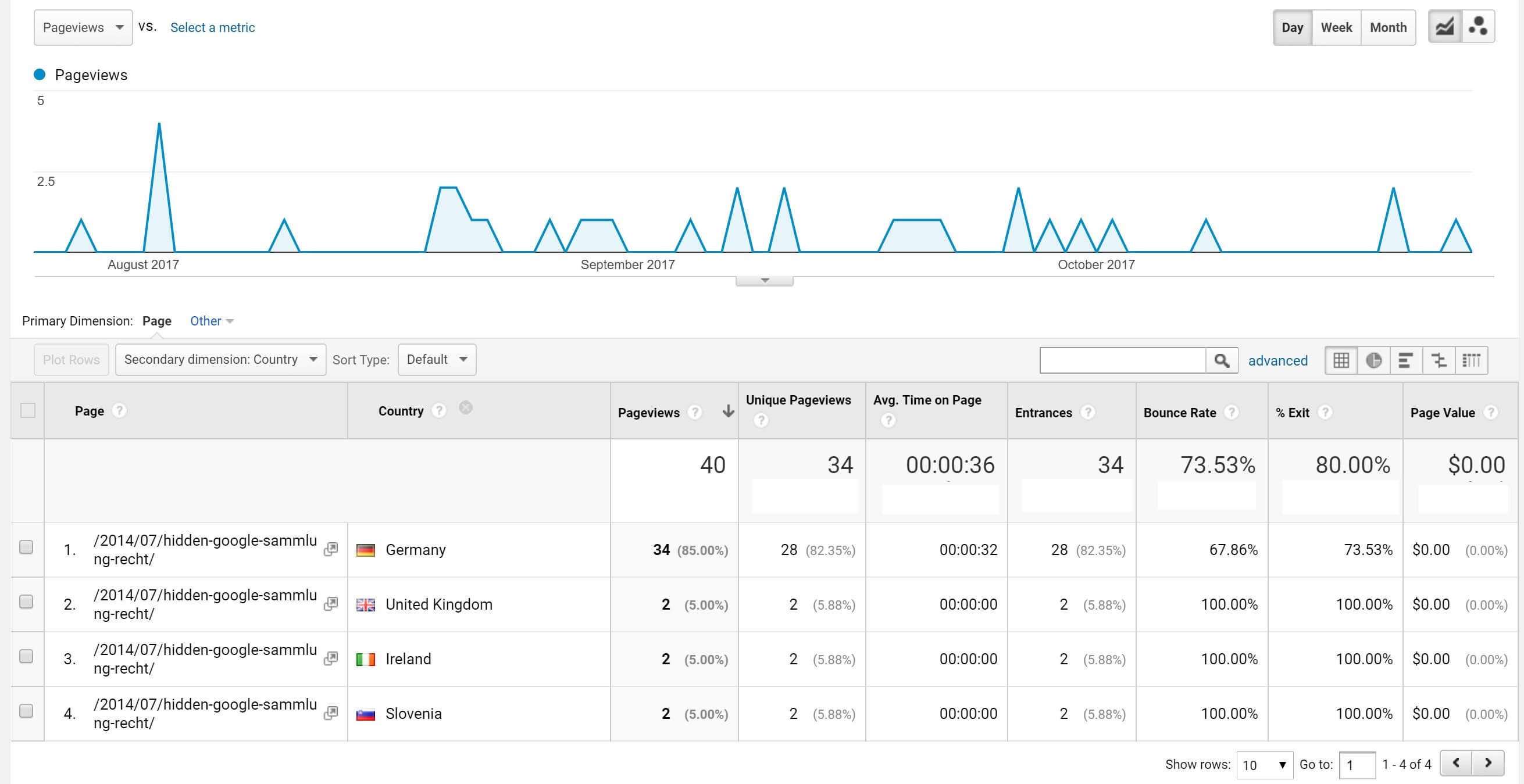
Also auf zu Google Analytics. In den letzten 90 Tagen gab es 40 Aufrufe des Artikels, wobei 85 Prozent aus Deutschland und 5 Prozent aus UK stammen. Da in unserem Artikel auf dem Screenshot nur Webseiten aus Deutschland und UK zu sehen sind, ist es sehr wahrscheinlich dass die löschende Person / Organisation in einem der beiden Länder sitzt. Mehr brauchbare Details gibt es leider nicht, da Google Analytics die Suchbegriffe kaum noch ausspuckt und vollständig zensiert.
Woher dieser Löschantrag nun kam und für welchen Suchbegriff sie gilt, lässt sich also leider nicht herausfinden. Da die Löschung aber auf Grundlage des europäischen Datenschutzrecht stattgefunden hat, muss es von einer der fünf Personen auf dem Screenshot ausgegangen sein, denn in Googles Bestimmungen heißt es „Wenn Sie einen solchen Antrag stellen, wägen wir Ihre Datenschutzrechte als Einzelperson gegen das öffentliche Interesse an den Informationen und das Recht auf Informationsverbreitung ab.“ Weiter heißt es aber leider auch, dass Google auch auf Nachfrage keine Informationen herausrückt.
Nun geht es nicht unbedingt nicht um diesen einen Artikel der in Europa unter einem bestimmten Suchbegriff nicht mehr zu finden ist – das werden wir überleben. Da wir aber keine Person in Textform erwähnt haben, keinen Link zu einer gelöschten Webseite anbieten (auch auf dem Screenshot ist nur die Domain zu sehen) und es auch keinerlei Informationen über die gelöschte Information gibt, fehlt meiner Meinung nach jede rechtliche Grundlage zur Löschung des Artikels. Auch die verlinkte Webseite existiert seit längerem nicht mehr.
Aus diesem Grund habe ich nun einfach einmal eine erneute Aktivierung der Webseite beantragt und werde sehen was geschieht, und ob der Antrag vielleicht wieder zurückgezogen wird. Eine Antwort von Google ist nicht garantiert, eine Bearbeitung hingegen schon. Falls es eine neue Entwicklung gibt, halte ich euch natürlich auf dem laufenden. Vielleicht gibt es ja doch noch auf irgendeine Art und Weise zusätzliche Informationen.
GoogleWatchBlog bei Google News abonnieren | GoogleWatchBlog-Newsletter
Teile diesen Artikel:





Jens, mit diesem Artikel hast Du Dich deutlich verrannt! Ich verstehe, dass Du Dich den ganzen Tag mit Google beschäftigst. Googles Geschäft sind Daten, also sollte sich, wer sich sich mit Google einlässt, darüber im Klaren sein, dass er Daten abgibt. Soweit so logisch.
Es gibt aber auch deutlich Grenzen, dieses „Abgebens“ – das heißt „Recht auf informationelle Selbstbestimmung“. Und wenn der EUGH als höchstes europäisches Gericht entscheidet, dass es das gibt, dann sind Sätze wie
„In diesem Artikel berichten wir über ein Webportal, dass dazu beitragen wollte, das Recht auf Vergessen in der geplanten Form etwas zu boykottieren – genau so, wie es Google durch diverse Maßnahmen ebenfalls getan hat.“
komplett daneben. Das wäre so wie wenn Glyphosat verboten wird, und dann kommt eine Firma die das mal nen bisschen boykottieren will… Geht gar nicht!
Ich glaube Du hast da vor lauter Bäumen den Wald ein bisschen aus den Augen verloren….
Natürlich muss man sich an Gesetze halten, aber man kann auch deren Lücken nutzen oder mehrere gegeneinander ausspielen – und das ist genau das, was ich mit „etwas boykottieren“ meine.
Weitere Infos dazu habe ich vor drei Jahren in diesem Artikel festgehalten:
https://www.googlewatchblog.de/2014/07/recht-vergessen-so-google/
Hi Jens. Interessant. Bleib dran – der Prozess und die Sicht auf Seite der „Betroffenen“ interessiert mich auch.
Ja klar Gesetzlücken kann und darf man nutzen.
Aber wenn man den sprichwörtlichen Schritt zurück geht: Worum geht es?
es gibt Daten, wer soll die Hoheit darüber haben? Der Betroffene oder Google? Also meiner Meinung nach definitiv der Betroffene, das sieht ja auch die Bundesregierung, EU und EUGH so… daher auch das Urteil (nicht nur das sondern auch das Safe Harbour Urteil gegen Facebook). Sich dann auf Lücken zu berufen, mag zwar im Einzelfall richtig sein, in der Gesamtschau bleibt es aber falsch, weil es der Idee zuwiderläuft.
Wenn einer von den Hanseln eben nicht auf dieser Liste auftauchen will, muss man das auch respektieren. Das sit ein hohes Gut.
Ich kann da auch aus eigener Erfahrung sprechen, als ich 15 war (2002) – haben wir uns gegen eine Abschlusszeitung entschieden, sondern eine Homepage gemacht. Da stand bei „immer in der Nähe von Alkohol“.
Mit 25 hab ich mich dann auf einen Job beworben, ein Jahr später meint mein Chef zu mir, dass er sich ja nicht sicher war, ob er mich einladen soll, weil ja komische Sachen im Netz stünden… ich bin vom Stuhl geflogen, dass bei meinem Namen das so unter den top drei bei Google auftauchte… Den Admin der Seite konnt eich nicht mehr ausfindig machen, weil nachdem sein Bruder starb, er zurück nach Russland gezogen ist…
Wenn man sich dann auf andere Jobs bewirbt, kann man nicht immer auf so coole Chefs hoffen… daher kam mir persönlich das Urteil sehr entgegen, klar bin ich damit auch subjektiv betroffen. Es gibt aber genügend andere Fälle wo die Hoheit pber die eigenen Daten wünschenswert wäre (Cybermobbing etc.) …
Natürlich wird das Problem nicht besser und zukünftige Generationen müssen da anders darauf vorbereitet werden, man sollte aber auch nicht allzu leichtfertig die eigenen Daten aus der Hand geben… weil genauso wie mir damals der Weitblick gefehlt hat, wissen wir auch nicht was mit unseren Daten in 10 Jahren passiert… IN Neuseeland gibt es bspw. smarte Stromzähler, und die Leute kriegen unterschiedliche Preise… teilweise auch nach Einkommen… in USA kann man sich als Partei einfach die Daten aller Volvo Käufer geben lassen (wählen gerne Demokraten) und macht dann Hausbesuche…
Nicht falsch verstehen, ich bin extrem technikaffin, ich denke nur man sollte es nicht übertreiben
@DFFVB: Ich verstehe deine Argumente. Aber solange das nicht vollumfänglich gedacht ist, bringt das auch nichts. Dann hätte dein Chef eben deinen Namen bei bing, duckduckgo oder damals wohl eher yahoo eingegeben. Oder die URL ist zwar weg, das Bild wird aber dennoch angezeigt und man gelangt darüber wieder auf die Seite. Ich könnte hier noch weiter ausholen, das Ganze ist einfach nicht durchdacht.
@Jens: Schau mal die Internetanbieter in Google Analytics an, welche auf die Seiten zugegriffen haben. Oft, wenn Firmen dahinter stecken, werden deren Zugriffe als eigene Internetanbieter in Google Analytics dargestellt.
Habe ich mir auch schon angesehen, hatte ich gleich als erstes gemacht
Da waren nur die normalen Provider zu sehen, kein Zugriff eines Unternehmens in den letzten drei Monaten. Deswegen tendiere ich auch dazu, dass es eine der fünf Personen sein muss.
@Stephan
Jein – wenn man Deine Argumentation zu Ende denkt, kommt man zu dem Schluss: Absolute Sicherheit kann es nicht geben, also kann man sich auch Sicherheitskontrollen am Flughafen sparen. Google hat nun mal die größte Reichweite und Marktabdeckung… es geht auch nicht um Google sondern um die marktbeherrschende Stellung… War ja bei MS und IE damals das gleiche.
Letztlich ist ein bisschen Schutz besser als keiner…
Hallo @Jens,
sowas gefällt mir mal gar nicht! Aus dem Grund lasse ich gerade mit YaCy einen Crawl über den Blog laufen, dann findet man den Artikel wenigsten bei dieser Suchmaschine weiterhin findet. Das dauert zwar ein bißchen, da mein „Server“ eigentlich ein alter Office-PC war. Aber das macht ja nichts, der läuft ja so oder so 24/7 durch!
Ich finde den Artikel sehr gut und er verstößt auch gegen nichts. Er ist hochgradig journalistisch, denn er will uns aufzeigen, wie der abstrakte Prozess des diktierten „Vergessens“ funktioniert. Und das ganze, ohne zu werten, ohne jemanden anzuprangern oder zu bejubeln. Ganz ausgezeichnet!