Die Ausgabe von Sprache durch einen Computer ist schon ein sehr alter Hut und wird seit Jahrzehnten von diversen Plattformen oder Programmen angeboten. Durch den Einzug der Sprach-Assistenten in unser digitales Leben ist diese Technologie aber sehr viel bedeutender geworden und wird von vielen Nutzern täglich verwendet. Bisher haben die Assistenten noch immer das ‚Problem‘, sehr künstlich und nicht menschlich zu klingeln. Googles KI-Tochter DeepMind hat sich dem nun angenommen und will mit der WaveNet-Technologie eine täuschend echte Sprachausgabe erzeugen.
Sei es nun Siri, Cortana oder Google Now – alle Assistenten können sowohl auf die Sprache des Nutzers hören, als auch selbst Informationen und Antworten per Sprache zurückgeben. Um im Alltag aber tatsächlich als „Assistent“ wahrgenommen zu werden, was das erklärte Ziel aller Anbieter ist, müssen nicht nur die Erkennungsalgorithmen und die Qualität der Antworten weiter verbessert werden, sondern auch der Ton der Sprachausgabe. Erst wenn man die Maschine nicht mehr vom Menschen unterscheiden kann, kann diese Konversation natürlicher wahrgenommen werden. Nicht wenigen Menschen ist die Kommunikation mit den heutigen Assistenten sogar peinlich.
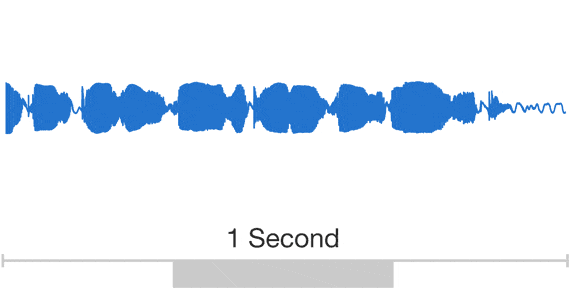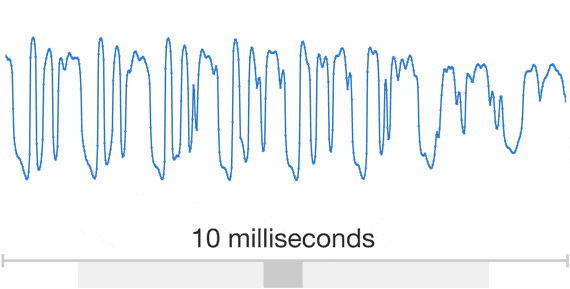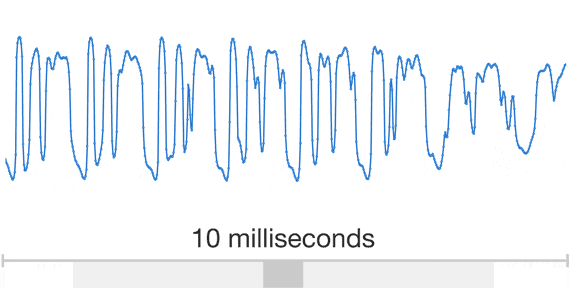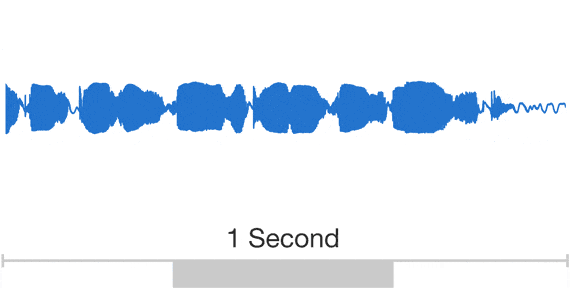
Auch Google möchte dass die Nutzer mit dem Google Assistant Konversationen führen, und dazu möchte man den Vorsprung bei der Qualität der Sprachausgabe weiter ausbauen. Statt wie bisher menschliche Sprecher ins Tonstudio zu stellen und diese tausende von Wörtern, Sätzen, Lauten und Bruchstücken vorlesen zu lassen, soll die Sprache in Zukunft komplett von einem Algorithmus erzeugt werden. Zu diesem Zweck wird die selbstentwickelte WaveNet-Technologie seit einiger Zeit mit Googles aktueller Sprachausgabe trainiert und soll so in Zukunft selbst Laute und Wörter erzeugen können.
Concatenative
Parametric
WaveNet
Der Vorteil der vollautomatischen Erzeugung von Sprache liegt auf der Hand: Es muss kein Sprecher mehr ins Studio geholt werden, die Sprache klingt sehr viel natürlicher als die teilweise sehr abgehackten Ausdrücke der aktuellen Maschinen und es kann sowohl die Sprache als auch die Stimme beliebig variiert werden. Obige Beispiele zeigen schon sehr gut den Unterschied zwischen den drei verwendeten Technologien. Der Unterschied ist gerade bei der WaveNet-Technologie deutlich hörbar und kann dann tatsächlich dafür sorgen, dass der Nutzer vergisst dass er sich mit einem Algorithmus und nicht mit einem Menschen unterhält.
Im Blogbeitrag von WaveNet gibt es noch viele weitere Beispiele und tiefere Erklärungen der Technologie, inklusive einiger Whitepapers. Diese geben einen guten Einblick in die Entwicklung, die sicherlich schon bald auch in Googles Sprachausgabe zu hören sein wird. Da das System aber nicht die Sprache an sich sondern nur die Wellen erzeugt, kann es auch für viele andere Zwecke eingesetzt werden und kann unter anderem auch Musik erzeugen. Im Beitrag gibt es eine Reihe von kurzen Songausschnitten, die lustigerweise von der Sprachausgabe erzeugt worden sind.
Und damit hätte Googles Künstliche Intelligenz wieder ein neues Einsatzgebiet gefunden, nachdem es sich erst vor kurzem als Mode-Designer oder auch Künstler betätigt hat.
» Ausführlicher Artikel im Deepmind-Blog