Recurrent Neural Networks: Neue Technologien sorgt für noch bessere und schnellere Google Spracherkennung

Googles Spracherkennung wurde im Laufe der Jahre immer weiter verbessert und hat mittlerweile eine sehr hohe Erkennungsrate. Selbst Dialekte, eine nuschelnde Aussprache oder laute Hintergrundgeräusche können mittlerweile sehr gut herausgefiltert und die gesprochenen Worte dennoch erkannt werden. Seit einigen Tagen soll diese Erkennungsrate nun noch weiter gestiegen und die Qualität der Erkennungen verbessert worden sein – und tatsächlich scheint die Spracherkennung mittlerweile unbeirrbar zu sein. Im Resarch-Blog wird nun erklärt, wie dies genau funktioniert.
Schon seit 2012 setzt Google zur Erkennung von Sprache auf neurale Netzwerke und hat dadurch eine sehr hohe Rate zur Erkennung erreichen können, doch jetzt hat man noch einige weitere Technologien dazu gepackt und verwendet lernende Algorithmen sowie verbesserte neurale Netzwerke. Statt wie bisher die gesprochene Sprache nur in Blöcken von 10 Millisekunden einzuteilen und diese einzeln zu durchlaufen, wird nun auch das gesamte Wort betrachtet und eine Verbindung zwischen den einzelnen Teilen hergestellt.
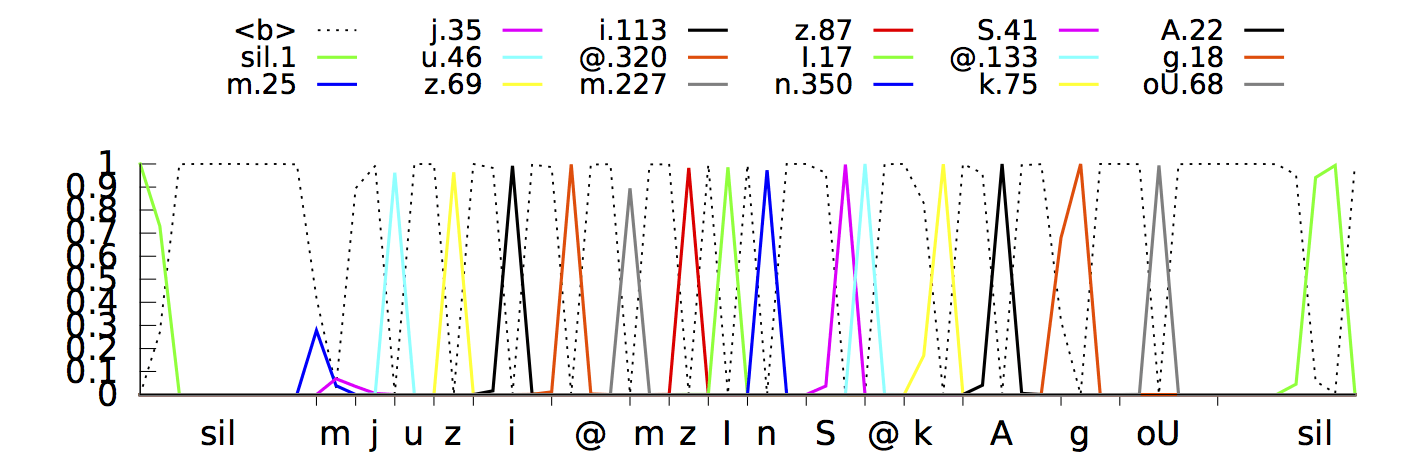
Anhand des Wortes „museum“, das in phonetischer Sprache „/m j u z i @ m/“ ausgesprochen wird, wird sehr gut erklärt wie die einzelnen Buchstaben erkannt werden und durch Zusammenhänge und Wahrscheinlichkeitsberechnungen das gesamte Wort nach und nach vom System zusammen gesetzt wird. Durch den Einsatz der neuen Technologie soll die gesamte Erkennung nun noch zuverlässiger und dennoch schneller sein – so dass man fast von einer Live-Erkennung sprechen kann. Die neue Technologie kommt sowohl auf Android als auch iOS und beim diktieren von Texten zum Einsatz.
Sehr interessanter Artikel, in dem viele Grundlagen der Technologien erstellt werden.
» Artikel im Google Research Blog
GoogleWatchBlog bei Google News abonnieren | GoogleWatchBlog-Newsletter
Teile diesen Artikel:





In der Programmierung gibt es keine „neurale Netzwerke“, sondern nur „neuronale Netzwerke“ ;D